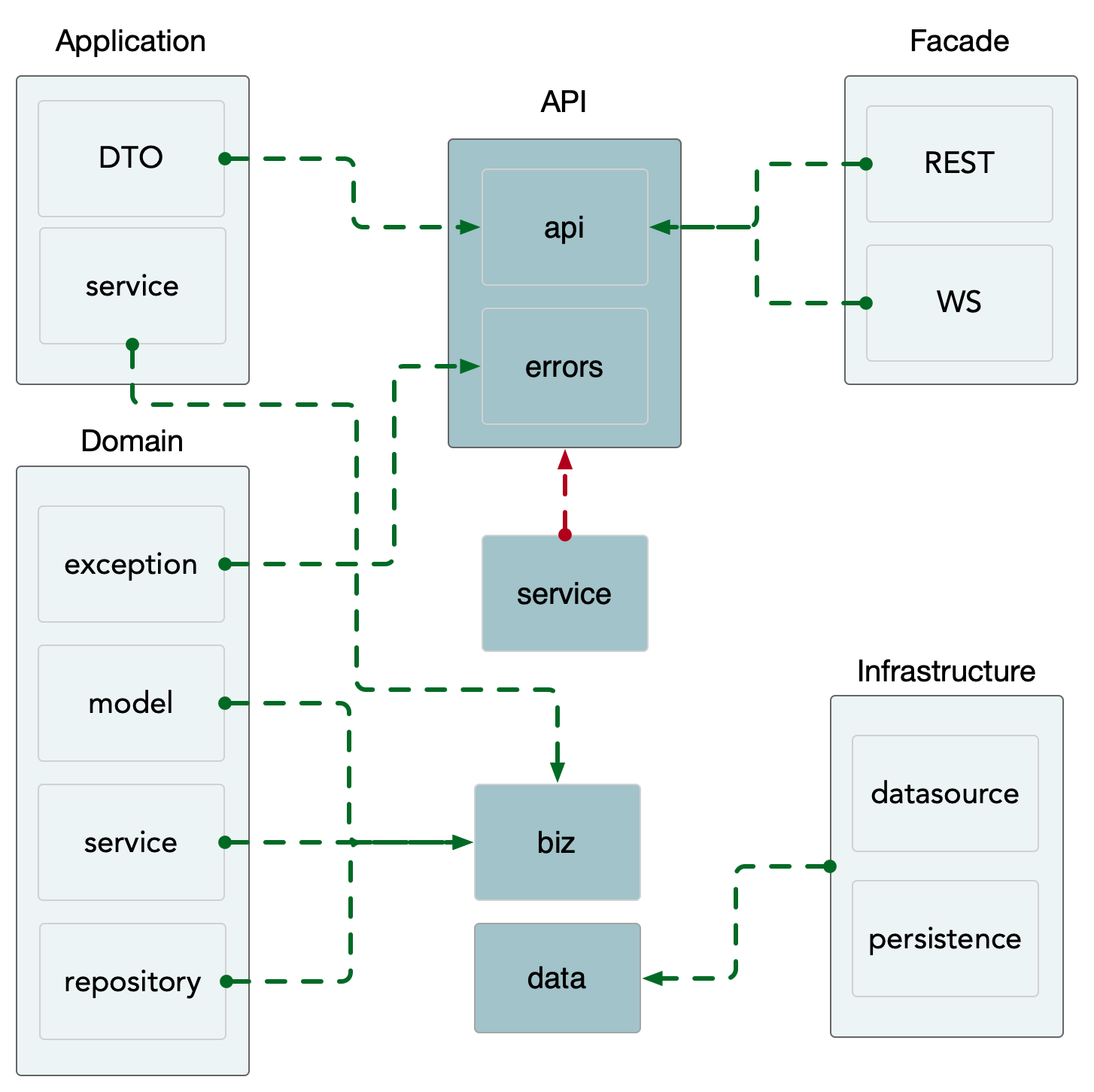
我们在微服务框架kratos v2的默认项目模板中kratos-layout使用了google/wire进行依赖注入,也建议开发者在维护项目时使用该工具。
wire 乍看起来比较违反直觉,导致很多同学不理解为什么要用或不清楚如何用(也包括曾经的我),本文来帮助大家理解 wire 的使用。
What
wire是由 google 开源的一个供 Go 语言使用的依赖注入代码生成工具。它能够根据你的代码,生成相应的依赖注入 go 代码。
而与其它依靠反射实现的依赖注入工具不同的是,wire 能在编译期(准确地说是代码生成时)如果依赖注入有问题,在代码生成时即可报出来,不会拖到运行时才报,更便于 debug。
Why
理解依赖注入
什么是依赖注入?为什么要依赖注入?
依赖注入就是 Java 遗毒(不是)
依赖注入 (Dependency Injection,缩写为 DI),可以理解为一种代码的构造模式(就是写法),按照这样的方式来写,能够让你的代码更加容易维护。
对于很多软件设计模式和架构的理念,我们都无法理解他们要绕好大一圈做复杂的体操、用奇怪的方式进行实现的意义。他们通常都只是丢出来一段样例,说这样写就很好很优雅,由于省略掉了这种模式是如何发展出来的推导过程,我们只看到了结果,导致理解起来很困难。那么接下来我们来尝试推导还原一下整个过程,看看代码是如何和为什么演进到依赖注入模式的,以便能够更好理解使用依赖注入的意义。
依赖是什么?
这里的依赖是个名词,不是指软件包的依赖(比如那坨塞在 node_modules 里面的东西),而是指软件中某一个模块(对象/实例)所依赖的其它外部模块(对象/实例)。
注入到哪里?
被依赖的模块,在创建模块时,被注入到(即当作参数传入)模块的里面。
不 DI 是啥样?DI 了又样子?
下面用 go 伪代码来做例子,领会精神即可。
假设个场景,你在打工搞一个 web 应用,它有一个简单接口。最开始的项目代码可能长这个样子:
# 下面为伪代码,忽略了很多与主题无关的细节
type App struct {
}
# 假设这个方法将会匹配并处理 GET /biu/<id> 这样的请求
func (a *App) GetData(id string) string {
# todo: write your data query
return "some data"
}
func NewApp() *App {
return &App{}
}
app := App()
app.Run()
你要做的是接一个 mysql,从里面把数据按照 id 查出来,返回。
要连 mysql 的话,假设我们已经有了个NewMySQLClient的方法返回 client 给你,初始化时传个地址进去就能拿到数据库连接,并假设它有个Exec的方法给你执行参数。
不用 DI,通过全局变量传递依赖实例
一种写法是,在外面全局初始化好 client,然后 App 直接拿来调用。
var mysqlUrl = "mysql://blabla"
var db = NewMySQLClient(mysqlUrl)
type App struct {
}
func (a *App) GetData(id string) string {
data := db.Exec("select data from biu where id = ? limit 1", id)
return data
}
func NewApp() *App {
return &App{}
}
func main() {
app := App()
app.Run()
}
这就是没用依赖注入,app 依赖了全局变量 db,这是比较糟糕的一种做法。db 这个对象游离在全局作用域,暴露给包下的其他模块,比较危险。(设想如果这个包里其他代码在运行时悄悄把你的这个 db 变量替换掉会发生啥)
不用 DI,在 App 的初始化方法里创建依赖实例
另一种方式是这样的:
type App struct {
db *MySQLClient
}
func (a *App) GetData(id string) string {
data := a.db.Exec("select data from biu where id = ? limit 1", id)
return data
}
func NewApp() *App {
return &App{db: NewMySQLClient(mysqlUrl)}
}
func main() {
app := NewApp("mysql://blabla")
app.Run()
}
这种方法稍微好一些,db 被塞到 app 里面了,不会有 app 之外的无关代码碰它,比较安全,但这依然不是依赖注入,而是在内部创建了依赖,接下来你会看到它带来的问题。
老板:我们的数据要换个地方存 (需要变更实现)
你的老板不知道从哪听说——Redis 贼特么快,要不我们的数据改从 Redis 里读吧。这个时候你的内心有点崩溃,但毕竟要恰饭的,就硬着头皮改上面的代码。
type App struct {
ds *RedisClient
}
func (a *App) GetData(id string) string {
data := a.ds.Do("GET", "biu_"+id)
return data
}
func NewApp() *App {
return &App{ds: NewRedisClient(redisAddr)}
}
func main() {
app := NewApp("redis://ooo")
app.Run()
}
上面基本进行了 3 处修改:
- App 初始化方法里改成了初始化 RedisClient
- get_data 里取数据时改用 run 方法,并且查询语句也换了
- App 实例化时传入的参数改成了 redis 地址
老板:要不,我们再换个地方存?/我们要加测试,需要 Mock
老板的思路总是很广的,又过了两天他又想换成 Postgres 存了;或者让你们给 App 写点测试代码,只测接口里面的逻辑,通常我们不太愿意在旁边再起一个数据库,那么就需要 mock 掉数据源这块东西,让它直接返回数据给请求的 handler 用,来进行针对性的测试。
这种情况怎么办?再改里面的代码?这不科学。
面向接口编程
一个很重要的思路就是要面向接口(interface)编程,而不是面向具体实现编程。
什么叫面向具体实现编程呢?比如上述的例子里改动的部分:调 mysqlclient 的 exec_sql 执行一条 sql,被改成了:调 redisclient 的 do 执行一句 get 指令。由于每种 client 的接口设计不同,每换一个实现,就得改一遍。
而面向接口编程的思路,则完全不同。我们不要听老板想用啥就马上写代码。首先就得预料到,这个数据源的实现很有可能被更换,因此在一开始就应该做好准备(设计)。
设计接口
Python 里面有个概念叫鸭子类型(duck-typing),就是如果你叫起来像鸭子,走路像鸭子,游泳像鸭子,那么你就是一只鸭子。这里的叫、走路、游泳就是我们约定的鸭子接口,而你如果完整实现了这些接口,我们可以像对待一个鸭子一样对待你。
在我们上面的例子中,不论是 Mysql 实现还是 Redis 实现,他们都有个共同的功能:用一个 id,查一个数据出来,那么这就是共同的接口。
我们可以约定一个叫 DataSource 的接口,它必须有一个方法叫 GetById,功能是要接收一个 id,返回一个字符串
type DataSource interface {
GetById(id string) string
}
然后我们就可以把各个数据源分别进行封装,按照这个 interface 定义实现接口,这样我们的 App 里处理请求的部分就可以稳定地调用 GetById 这个方法,而底层数据实现只要实现了 DataSource 这个 interface 就能花式替换,不用改 App 内部的代码了。
// 封装个redis
type redis struct {
r *RedisClient
}
func NewRedis(addr string) *redis {
return &redis{r: NewRedisClient(addr)}
}
func (r *redis) GetById(id string) string {
return r.r.Do("GET", "biu_"+id)
}
// 再封装个mysql
type mysql struct {
m *MySQLClient
}
func NewMySQL(addr string) *mysql {
return &mysql{m: NewMySQLClient(addr)}
}
func (m *mysql) GetById(id string) string {
return r.m.Exec("select data from biu where id = ? limit 1", id)
}
type App struct {
ds DataSource
}
func NewApp(addr string) *App {
//需要用Mysql的时候
return &App{ds: NewMySQLClient(addr)}
//需要用Redis的时候
return &App{ds: NewRedisClient(addr)}
}
由于两种数据源都实现了 DataSource 接口,因此可以直接创建一个塞到 App 里面了,想用哪个用哪个,看着还不错?
等一等,好像少了些什么
addr 作为参数,是不是有点简单?通常初始化一个数据库连接,可能有一堆参数,配在一个 yaml 文件里,需要解析到一个 struct 里面,然后再传给对应的 New 方法。
配置文件可能是这样的:
redis:
addr: 127.0.0.1:6379
read_timeout: 0.2s
write_timeout: 0.2s
解析结构体是这样的:
type RedisConfig struct {
Network string `json:"network,omitempty"`
Addr string `json:"addr,omitempty"`
ReadTimeout *duration.Duration `json:"read_timeout,omitempty"`
WriteTimeout *duration.Duration `json:"write_timeout,omitempty"`
}
结果你的NewApp方法可能就变成了这个德性:
func NewApp() *App {
var conf *RedisConfig
yamlFile, err := ioutil.ReadFile("redis_conf.yaml")
if err != nil {
panic(err)
}
err = yaml.Unmarshal(yamlFile, &conf)
if err != nil {
panic(err)
}
return &App{ds: NewRedisClient(conf)}
}
NewApp 说,停停,你们年轻人不讲武德,我的责任就是创建一个 App 实例,我只需要一个 DataSource 注册进去,至于这个 DataSource 是怎么来的我不想管,这么一坨处理 conf 的代码凭什么要放在我这里,我也不想关心你这配置文件是通过网络请求拿来的还是从本地磁盘读的,我只想把 App 组装好扔出去直接下班。
依赖注入终于可以登场了
还记得前面是怎么说依赖注入的吗?被依赖的模块,在创建模块时,被注入到(即当作参数传入)初始化函数里面。通过这种模式,正好可以让 NewApp 早点下班。我们在外面初始化好 NewRedis 或者 NewMysql,得到的 DataSource 直接扔给 NewApp。
也就是这样
func NewApp(ds DataSource) *App {
return &App{ds: ds}
}
那坨读配置文件初始化 redis 的代码扔到初始化 DataSource 的方法里去
func NewRedis() DataSource {
var conf *RedisConfig
yamlFile, err := ioutil.ReadFile("redis_conf.yaml")
if err != nil {
panic(err)
}
err = yaml.Unmarshal(yamlFile, &conf)
if err != nil {
panic(err)
}
return &redis{r: NewRedisClient(conf)}
}
更进一步,NewRedis 这个方法甚至也不需要关心文件是怎么读的,它的责任只是通过 conf 初始化一个 DataSource 出来,因此你可以继续把读 config 的代码往外抽,把 NewRedis 做成接收一个 conf,输出一个 DataSource
func GetRedisConf() *RedisConfig
func NewRedis(conf *RedisConfig) DataSource
因为之前整个组装过程是散放在 main 函数下面的,我们把它抽出来搞成一个独立的 initApp 方法。最后你的 App 初始化逻辑就变成了这样
func initApp() *App {
c := GetRedisConf()
r := NewRedis(c)
app := NewApp(r)
return app
}
func main() {
app := initApp()
app.Run()
}
然后你可以通过实现 DataSource 的接口,更换前面的读取配置文件的方法,和更换创建 DataSource 的方法,来任意修改你的底层实现(读配置文件的实现,和用哪种 DataSource 来查数据),而不用每次都改一大堆代码。这使得你的代码层次划分得更加清楚,更容易维护了。
这就是依赖注入。
手工依赖注入的问题
上文这一坨代码,把各个实例初始化好,再按照各个初始化方法的需求塞进去,最终构造出 app 的这坨代码,就是注入依赖的过程。
c := GetRedisConf()
r := NewRedis(c)
app := NewApp(r)
目前只有一个 DataSource,这样手写注入过程还可以,一旦你要维护的东西多了,比如你的 NewApp 是这样的NewApp(r *Redis, es *ES, us *UserSerivce, db *MySQL) *App然后其中 UserService 是这样的UserService(pg *Postgres, mm *Memcached),这样形成了多层次的一堆依赖需要注入,徒手去写非常麻烦。
而这部分,就是 wire 这样的依赖注入工具能够起作用的地方了——他的功能只是通过生成代码帮你注入依赖,而实际的依赖实例需要你自己创建(初始化)。
How
wire 的主要问题是,看文档学不会。反正我最初看完文档之后是一头雾水——这是啥,这要干啥?但通过我们刚才的推导过程,应该大概理解了为什么要用依赖注入,以及 wire 在这其中起到什么作用——通过生成代码帮你注入依赖,而实际的依赖实例需要你自己创建(初始化)。
接下来就比较清楚了。
首先要实现一个wire.go的文件,里面定义好 Injector。
// +build wireinject
func initApp() (*App) {
panic(wire.Build(GetRedisConf, NewRedis, SomeProviderSet, NewApp))
}
然后分别实现好 Provider。
执行wire命令后
他会扫描整个项目,并帮你生成一个wire_gen.go文件,如果你有什么没有实现好,它会报错出来。
你学会了吗?
重新理解
等一等,先别放弃治疗,让我们用神奇的中文编程来解释一下要怎么做。
谁参与编译?
上面那个initApp方法,官方文档叫它 Injector,由于文件里首行// +build wireinject这句注释,这个 wire.go 文件只会由 wire 读取,在 go 编译器在编译代码时不会去管它,实际会读的是生成的 wire_gen.go 文件。
而 Provider 就是你代码的一部分,肯定会参与到编译过程。
Injector 是什么鬼东西?
Injector 就是你最终想要的结果——最终的 App 对象的初始化函数,也就是前面那个例子里的initApp方法。
把它理解为你去吃金拱门,进门看到点餐机,噼里啪啦点了一堆,最后打出一张单子。
// +build wireinject
func 来一袋垃圾食品() 一袋垃圾食品 {
panic(wire.Build(来一份巨无霸套餐, 来一份双层鳕鱼堡套餐, 来一盒麦乐鸡, 垃圾食品打包))
}
这就是你点的单子,它不参与编译,实际参与编译的代码是由 wire 帮你生成的。
Provider 是什么鬼东西?
Provider 就是创建各个依赖的方法,比如前面例子里的 NewRedis 和 NewApp 等。
你可以理解为,这些是金拱门的服务员和后厨要干的事情: 金拱门后厨需要提供这些食品的制作服务——实现这些实例初始化方法。
func 来一盒麦乐鸡() 一盒麦乐鸡 {}
func 垃圾食品打包(一份巨无霸套餐, 一份双层鳕鱼堡套餐, 一盒麦乐鸡) 一袋垃圾食品 {}
wire 里面还有个 ProviderSet 的概念,就是把一组 Provider 打包,因为通常你点单的时候很懒,不想这样点你的巨无霸套餐:我要一杯可乐,一包薯条,一个巨无霸汉堡;你想直接戳一下就好了,来一份巨无霸套餐。这个套餐就是 ProviderSet,一组约定好的配方,不然你的点单列表(injector 里的 Build)就会变得超级长,这样你很麻烦,服务员看着也很累。
用其中一个套餐举例
// 先定义套餐内容
var 巨无霸套餐 = wire.NewSet(来一杯可乐,来一包薯条,来一个巨无霸汉堡)
// 然后实现各个食品的做法
func 来一杯可乐() 一杯可乐 {}
func 来一包薯条() 一包薯条 {}
func 来一个巨无霸汉堡() 一个巨无霸汉堡 {}
wire 工具做了啥?
重要的事情说三遍,通过生成代码帮你注入依赖。
在金拱门的例子里就是,wire 就是个服务员,它按照你的订单,去叫做相应的同事把各个食物/套餐做好,然后最终按需求打包给你。这个中间协调构建的过程,就是注入依赖。
这样的好处就是,
对于金拱门,假设他们突然换可乐供应商了,直接把来一杯可乐替换掉就行,返回一种新的可乐,而对于顾客不需要有啥改动。
对于顾客来说,点单内容可以变换,比如我今天不想要麦乐鸡了,或者想加点别的,只要改动我的点单(只要金拱门能做得出来),然后通过 wire 重新去生成即可,不需要关注这个服务员是如何去做这个订单的。
现在你应该大概理解 wire 的用处和好处了。
总结
让我们从金拱门回来,重新总结一下用 wire 做依赖注入的过程。
1. 定义 Injector
创建wire.go文件,定义下你最终想用的实例初始化函数例如initApp(即 Injector),定好它返回的东西*App,在方法里用panic(wire.Build(NewRedis, SomeProviderSet, NewApp))罗列出它依赖哪些实例的初始化方法(即 Provider)/或者哪些组初始化方法(ProviderSet)
2. 定义 ProviderSet(如果有的话)
ProviderSet 就是一组初始化函数,是为了少写一些代码,能够更清晰的组织各个模块的依赖才出现的。也可以不用,但 Injector 里面的东西就需要写一堆。
像这样 var SomeProviderSet = wire.NewSet(NewES,NewDB)定义 ProviderSet 里面包含哪些 Provider
3. 实现各个 Provider
Provider 就是初始化方法,你需要自己实现,比如 NewApp,NewRedis,NewMySQL,GetConfig 等,注意他们们各自的输入输出
4. 生成代码
执行 wire 命令生成代码,工具会扫描你的代码,依照你的 Injector 定义来组织各个 Provider 的执行顺序,并自动按照 Provider 们的类型需求来按照顺序执行和安排参数传递,如果有哪些 Provider 的要求没有满足,会在终端报出来,持续修复执行 wire,直到成功生成wire_gen.go文件。接下来就可以正常使用initApp来写你后续的代码了。
如果需要替换实现,对 Injector 进行相应的修改,实现必须的 Provider,重新生成即可。
它生成的代码其实就是类似我们之前需要手写的这个
func initApp() *App { // injector
c := GetRedisConf() // provider
r := NewRedis(c) // provider
app := NewApp(r) // provider
return app
}
由于我们的例子比较简单,通过 wire 生成体现不出优势,但如果我们的软件复杂,有很多层级的依赖,使用 wire 自动生成注入逻辑,无疑更加方便和准确。
5. 高级用法
wire 还有更多功能,比如 cleanup, bind 等等,请参考官方文档来使用。
最后,其实多折腾几次,就会使用了,希望本文能对您起到一定程度上的帮助。